信息熵和对比学习,为什么二分类任务中交叉熵和对比学习损失可以交换?
2024-09-09
1 min read
一个概率分布P的信息熵含量如下:
P(x)log(P(x))
KL散度基于信息熵,描述两个概率分布的差异:
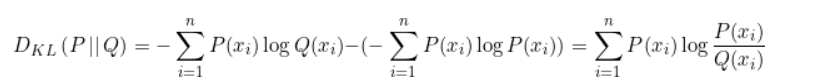
交叉熵和KL散度关系密切:
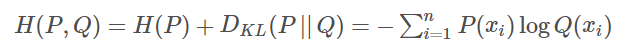
也就是KL散度为P、Q的交叉熵减去P的信息熵。
而KL散度中P的信息熵固定,因此,优化KL散度和优化交叉熵是一样的,就是少一项。
对比损失和交叉熵为什么可以交换
交叉熵损失函数如下:
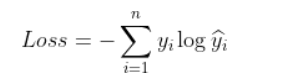
进行了softmax之后,公式为:
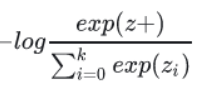
而infoNCE的损失函数为:
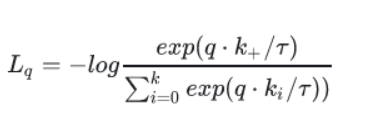
那么,可以将正样本看作标签为1的值,负样本为其他类别,进行交叉熵损失优化,效果一样。