Lora
2024-09-01
1 min read
PEFT中用Lora进行微调。
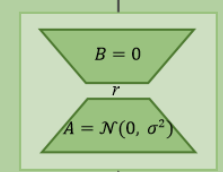
为什么Lora中训练时间和显存没有明显降低?
仍需要计算主要模型的梯度,来优化Lora的参数。
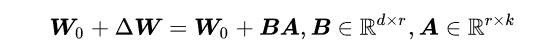
因此,反向传播的时候,对B和A求梯度得到的公式需要对W进行求梯度,也就是整个模型的梯度。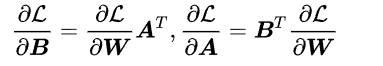
但由于不用求和存取优化器的参数(像Adam优化器需要维护每个参数的一阶动量和二阶动量,分别是梯度的指数移动平均值和梯度平方的指数移动平均值),因此LoRA在显存方面就只是节省了主干模型的优化器状态。